कॉन्फिडेंस इंटरवल
आत्मविश्वास अंतराल क्या है:
यह आँकड़ों में प्रयुक्त एक श्रेणी का एक अनुमान है, जिसमें जनसंख्या पैरामीटर होता है। यह अज्ञात जनसंख्या पैरामीटर एकत्रित डेटा से गणना किए गए एक नमूना मॉडल के माध्यम से पाया जाता है।
उदाहरण: एकत्र किए गए नमूने का औसत ̅ वास्तविक जनसंख्या माध्य μ से मेल खा सकता है या नहीं। इसके लिए, नमूने की एक श्रेणी पर विचार करना संभव है, जहां इस जनसंख्या का मतलब निहित हो सकता है। यह अंतराल जितना लंबा होगा, इस होने की संभावना उतनी ही अधिक होगी।
विश्वास अंतराल को एक प्रतिशत के रूप में व्यक्त किया जाता है, जो विश्वास के स्तर से सम्बद्ध होता है, जिसमें ९ ०%, ९ ५% और ९९% सबसे अधिक संकेत होते हैं। नीचे दी गई छवि में, उदाहरण के लिए, हमारे पास इसकी ऊपरी और निचली सीमाओं (ए -ए ) के बीच 90% विश्वास अंतराल है।
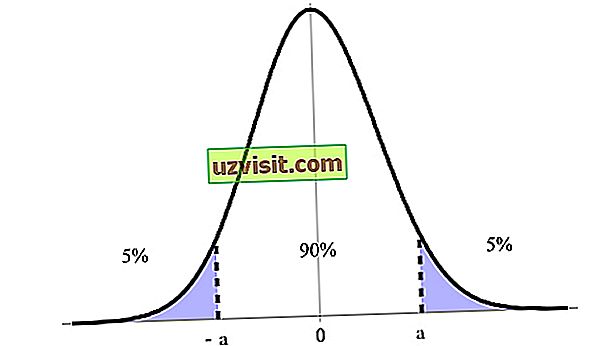
कॉन्फिडेंस इंटरवल आँकड़ों में परिकल्पना परीक्षण के भीतर सबसे महत्वपूर्ण अवधारणाओं में से एक है, क्योंकि इसका उपयोग अनिश्चितता के उपाय के रूप में किया जाता है। यह शब्द पोलिश गणितज्ञ और सांख्यिकीविद जेरज़ी नेमन द्वारा 1937 में पेश किया गया था।
कॉन्फिडेंस इंटरवल की प्रासंगिकता क्या है?
एक गणना के खिलाफ अनिश्चितता (या अविश्वास) के मार्जिन को इंगित करने के लिए आत्मविश्वास अंतराल महत्वपूर्ण है। यह गणना स्रोत जनसंख्या में परिणाम के वास्तविक आकार का अनुमान लगाने के लिए अध्ययन नमूने का उपयोग करती है।
विश्वास अंतराल की गणना एक रणनीति है जो त्रुटि नमूनाकरण पर विचार करती है। आपके अध्ययन के परिणाम का आकार और आपका आत्मविश्वास मूल आबादी के लिए निर्धारित मूल्यों की विशेषता है।
विश्वास अंतराल जितना संकीर्ण होता है, अध्ययन की आबादी के प्रतिशत की उतनी अधिक संभावना होती है कि स्रोत जनसंख्या की वास्तविक संख्या का प्रतिनिधित्व करता है, अध्ययन वस्तु के परिणाम के रूप में अधिक निश्चितता देता है।
कॉन्फिडेंस इंटरवल की व्याख्या कैसे करें?
आत्मविश्वास अंतराल की सही व्याख्या शायद इस सांख्यिकीय अवधारणा का सबसे चुनौतीपूर्ण पहलू है। अवधारणा की सबसे आम व्याख्या का एक उदाहरण निम्नलिखित है:
एक 95% संभावना है कि, भविष्य में, जनसंख्या पैरामीटर (जैसे औसत) का सही मूल्य एक्स (निचली सीमा) और वाई (ऊपरी सीमा) में आता है।
इस प्रकार, विश्वास अंतराल की व्याख्या निम्न प्रकार से की जाती है: यह 95% आश्वस्त है कि X (निम्न बाउंड) और Y (ऊपरी बाउंड) के बीच के अंतराल में जनसंख्या पैरामीटर का सही मान होता है।
यह बताना पूरी तरह से गलत होगा कि: वहाँ एक 95% संभावना है कि X (निचला बाउंड) और Y (ऊपरी बाउंड) के बीच के अंतराल में जनसंख्या पैरामीटर का वास्तविक मान होता है।
उपरोक्त कथन विश्वास अंतराल के बारे में सबसे आम गलत धारणा है। सांख्यिकीय श्रेणी की गणना करने के बाद, इसमें केवल जनसंख्या पैरामीटर हो सकता है या नहीं।
हालाँकि, अंतराल नमूनों के बीच भिन्न हो सकते हैं, जबकि सही जनसंख्या पैरामीटर नमूने की परवाह किए बिना समान है।
इसलिए, विश्वास अंतराल विश्वास कथन केवल उस मामले में बनाया जा सकता है जहां आत्मविश्वास अंतराल नमूने की संख्या के लिए पुनर्गणना किए जाते हैं।
कॉन्फिडेंस इंटरवल की गणना के चरण
सीमा की गणना निम्न चरणों का उपयोग करके की जाती है:
- नमूना डेटा इकट्ठा करें: एन ;
- नमूना की गणना करें x̅;
- निर्धारित करें कि क्या जनसंख्या मानक विचलन ( σ ) ज्ञात या अज्ञात है;
- यदि जनसंख्या मानक विचलन ज्ञात है, तो एक z- बिंदु का उपयोग संबंधित आत्मविश्वास स्तर के लिए किया जा सकता है;
- यदि जनसंख्या मानक विचलन अज्ञात है, तो हम संबंधित आत्मविश्वास स्तर के लिए एक आंकड़ा टी का उपयोग कर सकते हैं;
- इस प्रकार, निम्न अंतराल के उपयोग से विश्वास अंतराल की निचली और ऊपरी सीमाएं पाई जाती हैं:
क) ज्ञात जनसंख्या का मानक विचलन :
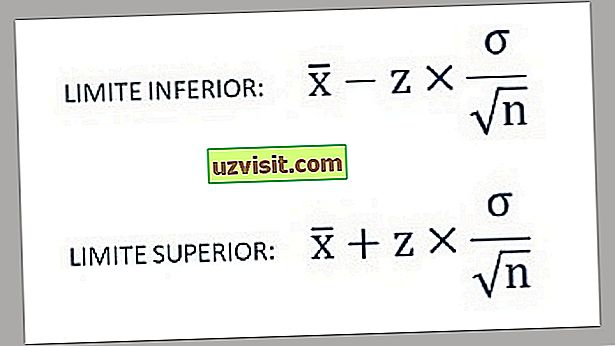
ज्ञात जनसंख्या के मानक विचलन की गणना के लिए सूत्र।
बी) एक अज्ञात आबादी का मानक विचलन :

अज्ञात आबादी के मानक विचलन की गणना के लिए सूत्र।
आत्मविश्वास अंतराल का व्यावहारिक उदाहरण
एक नैदानिक अध्ययन ने वयस्कों में अस्थमा की उपस्थिति और ऑब्सट्रक्टिव स्लीप एपनिया के विकास के जोखिम के बीच संबंध का मूल्यांकन किया।
कुछ वयस्कों को चार साल के लिए राज्य के अधिकारियों की सूची से बेतरतीब ढंग से भर्ती किया गया था।
अस्थमा के साथ प्रतिभागियों, जब बिना उन लोगों की तुलना में, चार साल में एपनिया विकसित करने का अधिक जोखिम था।
इस तरह के नैदानिक अनुसंधान का संचालन करने में, ब्याज की आबादी का एक सबसेट आमतौर पर अध्ययन दक्षता (कम लागत और कम लागत) बढ़ाने के लिए भर्ती किया जाता है।
व्यक्तियों का यह उपसमूह, अध्ययन की गई आबादी, उन लोगों से बना है जो समावेश मानदंडों को पूरा करते हैं और अध्ययन में भाग लेने के लिए सहमत हैं, जैसा कि नीचे दी गई छवि में दिखाया गया है।

फिर, अध्ययन पूरा हो गया है और एक प्रभाव आकार (उदाहरण के लिए, एक अंतर अंतर या रिश्तेदार जोखिम ) की गणना अनुसंधान प्रश्न का उत्तर देने के लिए की जाती है।
इस प्रक्रिया, जिसे इंट्रेंस कहा जाता है, में अध्ययन की आबादी से एकत्र आंकड़ों का उपयोग ब्याज की आबादी पर वास्तविक प्रभाव के आकार का अनुमान लगाने के लिए किया जाता है, अर्थात मूल की आबादी।
दिए गए उदाहरण में, शोधकर्ताओं ने राज्य कर्मचारियों (स्रोत आबादी) का एक यादृच्छिक नमूना भर्ती किया, जो अध्ययन (अध्ययन आबादी) में भाग लेने के लिए पात्र और सहमत थे और उन्होंने बताया कि अस्थमा अध्ययन आबादी में एपनिया के विकास का खतरा बढ़ाता है।
ब्याज की आबादी के केवल एक उपसमूह की भर्ती के कारण एक नमूना त्रुटि के लिए खाते में, उन्होंने 1.06 - 1.82 के 95% विश्वास अंतराल (अनुमान के आसपास) की गणना की, 95 की संभावना का संकेत स्रोत जनसंख्या में वास्तविक सापेक्ष जोखिम 1.06 और 1.82 के बीच होगा ।
औसत के लिए आत्मविश्वास अंतराल
जब किसी के पास आबादी के मानक विचलन की जानकारी होती है, तो कोई उस आबादी के औसत या औसत के लिए एक विश्वास अंतराल की गणना कर सकता है।
जब एक सांख्यिकीय विशेषता जिसे मापा जा रहा है (जैसे आय, आईक्यू, मूल्य, ऊंचाई, मात्रा या वजन) संख्यात्मक है, तो ज्यादातर मामलों में यह अनुमान लगाया जाता है कि आबादी के लिए औसत मूल्य पाया जाता है।
इस प्रकार, हम त्रुटि के मार्जिन के साथ एक नमूना माध्य ( x, ) का उपयोग करके जनसंख्या माध्य ( μ ) को खोजने की कोशिश करते हैं। इस गणना के परिणाम को जनसंख्या माध्य के लिए विश्वास अंतराल कहा जाता है ।
जब जनसंख्या मानक विचलन ज्ञात हो जाता है, तो जनसंख्या के मतलब के लिए आत्मविश्वास अंतराल (CI) का सूत्र है:

जहां:
- x नमूना माध्य है;
- standard जनसंख्या मानक विचलन है;
- n नमूना आकार है;
- Level * अपने इच्छित आत्मविश्वास स्तर के लिए सामान्य मानक वितरण के उचित मूल्य का प्रतिनिधित्व करता है।
विभिन्न आत्मविश्वास स्तरों (: * ) के लिए निम्नलिखित मूल्य हैं:
| ट्रस्ट का स्तर | Z * का मान - |
|---|---|
| 80% | 1:28 |
| 90% | 1.645 (पारंपरिक) |
| 95% | 1.96 |
| 98% | 2:33 |
| 99% | 2:58 |
उपरोक्त तालिका प्रदान की गई आत्मविश्वास स्तरों के लिए z * मान दिखाती है। ध्यान दें कि ये मान मानक सामान्य वितरण (Z-) से प्राप्त किए जाते हैं।
प्रत्येक z * मान और इस मान के ऋणात्मक के बीच का क्षेत्र (अनुमानित) विश्वास प्रतिशत है। उदाहरण के लिए, z * = 1.28 और z = -1.28 के बीच का क्षेत्र लगभग 0.80 है। इसलिए, इस तालिका को अन्य विश्वास प्रतिशत में भी विस्तारित किया जा सकता है। तालिका केवल विश्वास के सबसे अधिक उपयोग किए जाने वाले प्रतिशत को दिखाती है।
हाइपोथीसिस का अर्थ भी देखें।


